 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorlds Within Words: Translating Culture in Ancient Chinese Texts with Multi-Agent Coordination
May 31, 2026Large language model (LLM)-based machine translation has advanced cross-cultural communication, yet it still struggles with culture-loaded words (CLWs) in ancient Chinese texts. The challenge extends beyond lexical alignment to deciding when and how culture-dependent knowledge should be explicated for readers lacking relevant background. Literal translation often preserves surface forms while missing underlying concepts, whereas over-explicitation harms conciseness and readability. To address this problem, we formulate CLW translation as a selective explicitation task and propose \textbf{MACAT}, a \textbf{M}ulti-\textbf{A}gent \textbf{C}ulture-\textbf{A}ware \textbf{T}ranslation framework that dynamically identifies culturally salient phrases and injects concise explanatory knowledge when necessary. MACAT further incorporates a quality-aware reranking module for candidate selection and a multi-round evaluation agent that assesses translations across terminological precision, readability, fidelity, cultural preservation, and cultural explicitation. Experiments on traditional Chinese medicine (TCM) classics and the \textit{Analects} show that, under a unified GPT-5.4 evaluation setting, MACAT consistently outperforms both the backbone model and general-purpose MT baselines on 100 TCM documents and a 20-chapter subset of the \textit{Analects}.
CLIF: Concept-Level Influence Functions for Transparent Bottleneck Models
May 19, 2026In recent years, the black-box nature of deep learning models has limited their application in high-stakes domains such as medical diagnosis and finance, where interpretability is essential. To address this, we propose a novel approach using influence functions to enhance interpretability in NLP models at both the sample and concept levels. Experiments on CEBaB and Yelp datasets show that influence functions effectively identify the most impactful training samples, both helpful and harmful, on model predictions. By adjusting the labels and weights of these samples, we demonstrate that model performance can be restored to baseline levels without retraining, confirming the value of influence functions for efficient data debugging. Furthermore, our concept-level analysis identifies key concepts within Concept Bottleneck Models (CBM) that significantly affect predictions. Modifying these concepts alters model behavior observably, providing clear insights into the decision process.
Agri-CPJ: A Training-Free Explainable Framework for Agricultural Pest Diagnosis Using Caption-Prompt-Judge and LLM-as-a-Judge
Apr 26, 2026Crop disease diagnosis from field photographs faces two recurring problems: models that score well on benchmarks frequently hallucinate species names, and when predictions are correct, the reasoning behind them is typically inaccessible to the practitioner. This paper describes Agri-CPJ (Caption-Prompt-Judge), a training-free few-shot framework in which a large vision-language model first generates a structured morphological caption, iteratively refined through multi-dimensional quality gating, before any diagnostic question is answered. Two candidate responses are then generated from complementary viewpoints, and an LLM judge selects the stronger one based on domain-specific criteria. Caption refinement is the component with the largest individual impact: ablations confirm that skipping it consistently degrades downstream accuracy across both models tested. On CDDMBench, pairing GPT-5-Nano with GPT-5-mini-generated captions yields \textbf{+22.7} pp in disease classification and \textbf{+19.5} points in QA score over no-caption baselines. Evaluated without modification on AgMMU-MCQs, GPT-5-Nano reached 77.84\% and Qwen-VL-Chat reached 64.54\%, placing them at or above most open-source models of comparable scale despite the format shift from open-ended to multiple-choice. The structured caption and judge rationale together constitute a readable audit trail: a practitioner who disagrees with a diagnosis can identify the specific caption observation that was incorrect. Code and data are publicly available https://github.com/CPJ-Agricultural/CPJ-Agricultural-Diagnosis
Bridging Music and Text with Crowdsourced Music Comments: A Sequence-to-Sequence Framework for Thematic Music Comments Generation
Sep 05, 2022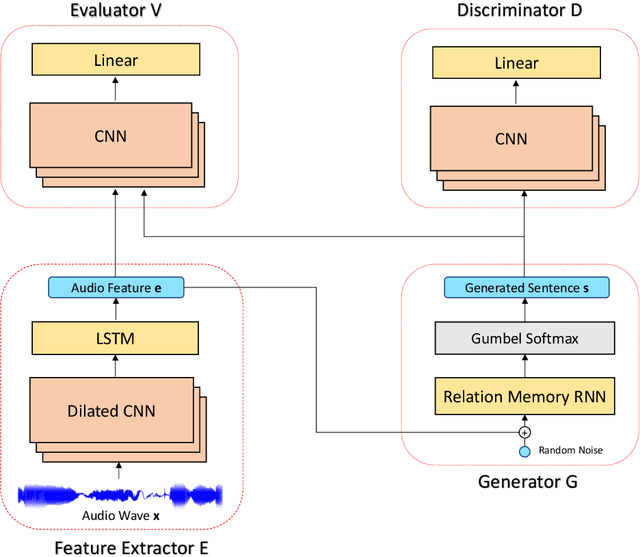
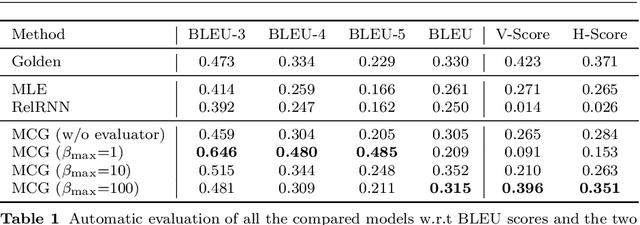
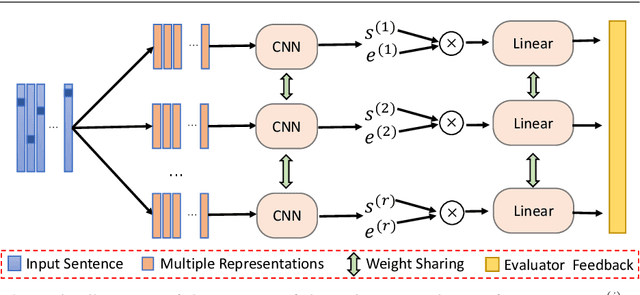

We consider a novel task of automatically generating text descriptions of music. Compared with other well-established text generation tasks such as image caption, the scarcity of well-paired music and text datasets makes it a much more challenging task. In this paper, we exploit the crowd-sourced music comments to construct a new dataset and propose a sequence-to-sequence model to generate text descriptions of music. More concretely, we use the dilated convolutional layer as the basic component of the encoder and a memory based recurrent neural network as the decoder. To enhance the authenticity and thematicity of generated texts, we further propose to fine-tune the model with a discriminator as well as a novel topic evaluator. To measure the quality of generated texts, we also propose two new evaluation metrics, which are more aligned with human evaluation than traditional metrics such as BLEU. Experimental results verify that our model is capable of generating fluent and meaningful comments while containing thematic and content information of the original music.